Leverage AI for Mock Tables and Charts When Testing Prototypes利用生成式 AI 最佳化原型測試中的表格和圖表
為原型設計建立逼真的資料非常耗時,尤其是在設計還未完全成型、時間緊迫或僅由一人負責使用者體驗(UX)工作的情況下。生成式 AI 可以透過合理編寫提示詞(Prompt)來幫助快速生成高質量的表格和圖表,從而提高測試資料的真實性。
為什麼要關注表格和圖表的真實性
在原型測試中,使用者可能會仔細審查表格和圖表資料的準確性。研究表明,當參與者面對不熟悉的資料時,他們往往會花更多時間尋找異常值和不一致之處。因此,即使表格和圖表只是用於測試的原型,它們的內容也需要儘量做到真實可信。
如何使用生成式 AI 建立更真實的表格和圖表
1. 謹慎使用真實資料
當使用生成式 AI 處理資料時,確保遵循公司和法規的安全政策。切勿在未經批准的情況下向 AI 工具提供敏感或可識別的真實資料。
2. 構建 Prompt 框架
在生成資料前,先整理資料生成的目標和要求,構建一個“Prompt 框架”(類似於線框圖)。這樣可以更好地與同事溝通,併為生成式 AI 編寫有效的提示詞。
3. 生成表格資料的 7 種策略
上下文相關性:確保生成的資料與目標使用者的背景一致。例如,如果你正在測試一個針對小型企業的應用程式,就不要使用大企業的資料模型。指定業務規模、行業、地域等資訊,使資料更貼近實際使用情景。

定義資料量:明確你希望生成的表格行數。儘管原型中可能只需幾十行資料,但 AI 生成的資料應考慮到整個資料集的規模。透過告知 AI 資料總量(如年收入總額或交易總量),生成的樣本資料會更符合實際情況。

資料排序:若表格資料需要特定的排序方式(如按銷售額、時間等排序),可直接在提示詞中說明,而無需手動排序。
資料屬性和格式:提示 AI 使用唯一值、固定選項(如“狀態”列只能是“進行中”或“已完成”)、特定格式(如日期格式)及合理範圍(如評分從 1 到 5)。
基於圖表生成表格:如果已有設計好的圖表,可以上傳圖表讓 AI 基於圖表資料生成相應的表格。AI 可利用圖表的視覺資訊來反向推測資料。

資料分佈控制:根據原型測試需要,提示 AI 使用特定的資料分佈模式,如正態分佈、帕累託分佈(少數資料產生大多數影響)或自定義分佈。

驗證與校對:指定 AI 使用程式設計工具(如 Python)來計算資料,並要求它展示詳細的計算過程和驗證結果,以確保生成資料的準確性。
生成圖表資料的 7 種策略
- 描述圖表內容:用自然語言描述趨勢,如"收入整體下降,12月小幅上升"。
- 簡化圖表:去除不必要的網格線、陰影或圖例。
- 突出異常值:用特殊顏色或標註顯示指定的異常資料點。
- 指定尺寸:提供圖表尺寸,避免反覆調整。
- 使用 SVG:生成 SVG 格式圖表,便於編輯。
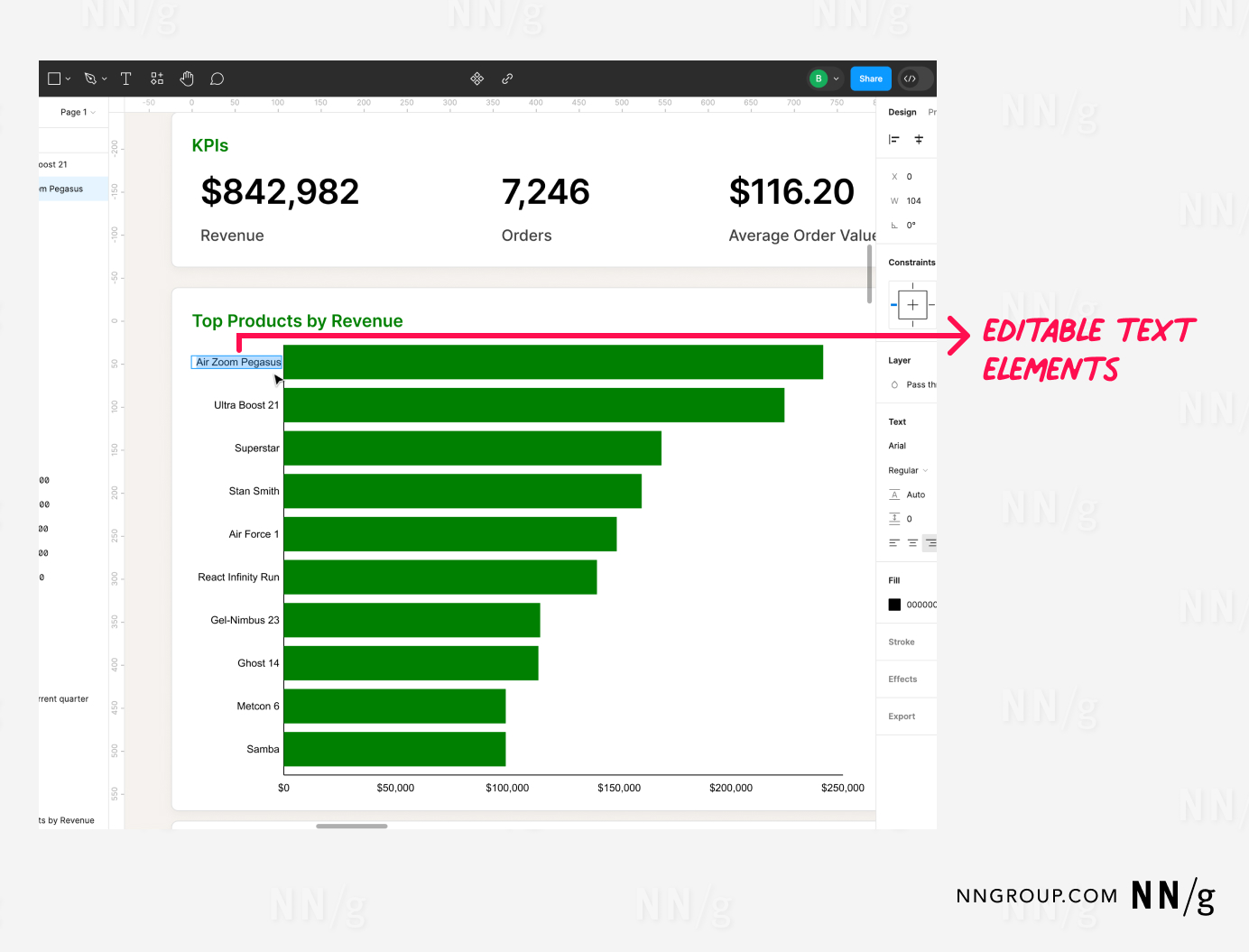
SVG格式的圖表便於在Figma等設計工具中匯入和編輯。
- 避免依賴 AI 進行批判性思考:AI 可能會生成不合邏輯或誤導的圖表內容,因此務必檢查生成結果,確保其符合資料視覺化的最佳實踐。
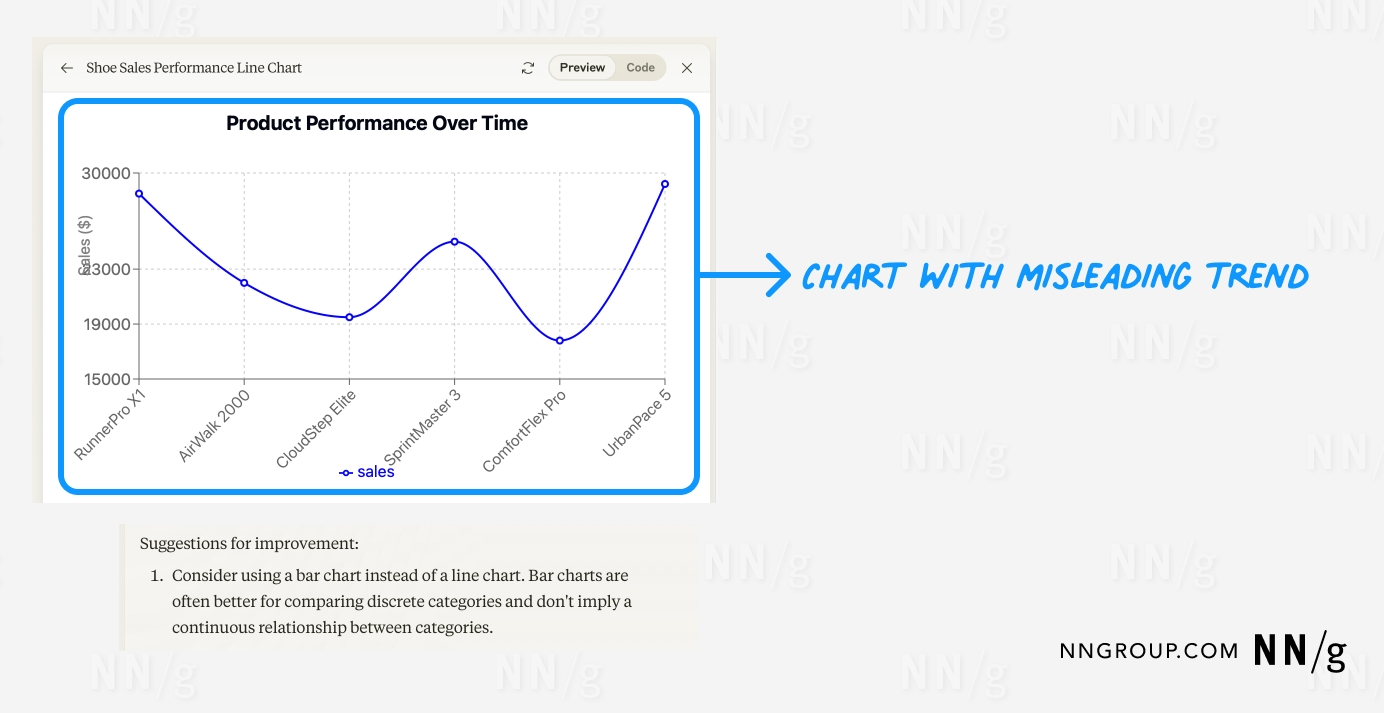
提供表格資料以生成圖表:向 AI 提供一組表格資料,並要求生成不同型別的圖表。可以快速生成多個圖表選項以便選擇。
匯入生成的表格和圖表
圖表:直接複製貼上SVG檔案到設計工具。表格:使用Figma外掛(如Google Sheets Sync)匯入,但注意使用障礙和隱私問題。
專業工具(如Axure)可匯入CSV檔案,支援互動功能,但過多資料可能影響效能。建議僅匯入測試所需資料。
AI工具生成資料的差異
Claude 3.5 Sonnet:表格和圖表生成穩定,但數值計算存在誤差。
ChatGPT 4:可驗證數值精度,但有時不遵循提示要求。五、合成資料的應用
合成資料保留統計特徵,剔除敏感資訊,適用於醫療、金融等高度監管行業,既模擬真實場景又保護隱私。
生成式AI提高資料密集型應用原型測試的內容真實性,使建立逼真資料更加高效。